Back to Blog
Enterprise AIOctober 8, 202520 min readHelix AI
The Reasoning Runtime for Enterprise Intelligence
Summary
The Hidden Execution Layer of Business
From ETL to RTL: Reasoning Transform & Load
Traditional Stack: Reasoning Stack:
┌─────────────┐ ┌──────────────────┐
│ Sources │ │ Logic Sources │
├─────────────┤ ├──────────────────┤
│ CSV, JSON │ │ .xlsx, .docx, │
│ APIs, DBs │ │ .pdf, .pptx, │
└─────┬───────┘ │ emails, Slack, │
│ │ audio, video │
▼ └────────┬─────────┘
┌─────────────┐ │
│ Transform │ ▼
├─────────────┤ ┌──────────────────┐
│ Clean, │ │ Parse + Graph │
│ Normalize │ ├──────────────────┤
└─────┬───────┘ │ Extract formulas │
│ │ Map dependencies │
▼ │ Resolve refs │
┌─────────────┐ │ Classify entities│
│ Load │ └────────┬─────────┘
├─────────────┤ │
│ Warehouse │ ▼
│ Lake/house │ ┌──────────────────┐
└─────────────┘ │ Reasoning Layer │
├──────────────────┤
│ Semantic index │
│ Constraint engine│
│ Scenario runtime │
└──────────────────┘
The Multi-Modal Platform
The Platform Architecture
helix_platform:
modalities:
structured:
- Spreadsheets (.xlsx, .csv, Google Sheets)
- Databases (SQL, NoSQL)
- APIs (REST, GraphQL)
documents:
- PDFs (contracts, reports, statements)
- Word docs (policies, procedures)
- Presentations (decks, proposals)
communications:
- Email (threads, attachments)
- Slack/Teams (channels, DMs)
- Meeting transcripts
media:
- Audio files (earnings calls, meetings)
- Video (presentations, walkthroughs)
- Images (diagrams, whiteboards)
- Handwritten notes (sketches, annotations)
parsing_layer:
# Each modality has specialized extractors
excelerate: "Spreadsheet logic extraction"
rainfall: "Unstructured text processing"
document_intelligence: "Contract & report parsing"
media_processor: "Audio/video/image analysis"
graph_layer:
# Unified semantic representation
logic_nodes: "Formulas, constraints, entities"
dependencies: "References, derivations, conflicts"
provenance: "Source tracking and lineage"
reasoning_layer:
# Where intelligence operates
semantic_index: "Vector search over logic"
constraint_engine: "Policy enforcement"
scenario_runtime: "What-if simulation"
explanation_engine: "Natural language reasoning"
Why Deep Extraction Matters (And Why RAG Isn't Enough)
Excelerate: Our Spreadsheet Reasoning Engine & Processor
What Makes Spreadsheet Extraction Hard
=IF(Sales!B2>1000000, VLOOKUP(A2,Customers,3,FALSE), 0)
What makes workbooks get this large?
| Category | Typical Contributors | Why Size Explodes |
|---|---|---|
| Multiple scenario tabs | "Base", "Upside", "Downside" monthly detail | Dozens of near-identical sheets duplicating large formula ranges |
| Heavy formulas | Array formulas, volatile functions (OFFSET, INDIRECT, SUMIFS) | Excel stores dependency trees for each |
| Data imports | Raw transactions, pivot caches, Power Query data | Uncompressed CSV-like tables embedded |
| Formatting | Conditional formatting, rich cell styles | Excel stores each rule individually |
| Embedded objects | Charts, images, VBA modules | Binary blobs add up quickly |
| Historical data | 10-year monthly financials (120 cols x 1000 rows x many sheets) | Each cell carries metadata |
The Four Channels: How We Actually Read a Spreadsheet
| Channel | What It Captures | Why It Matters |
|---|---|---|
| Grid (Structure) | Sheet layout, ranges, sections, hierarchies | Defines scope and context of logic |
| Formulas (Logic) | Functions, dependencies, calculations | Encodes business rules |
| Text (Semantics) | Labels, headers, comments, notes | Links data to domain language |
| Visual (Emphasis) | Formatting, colors, validations | Signals importance and constraints |
The Extraction Pipeline
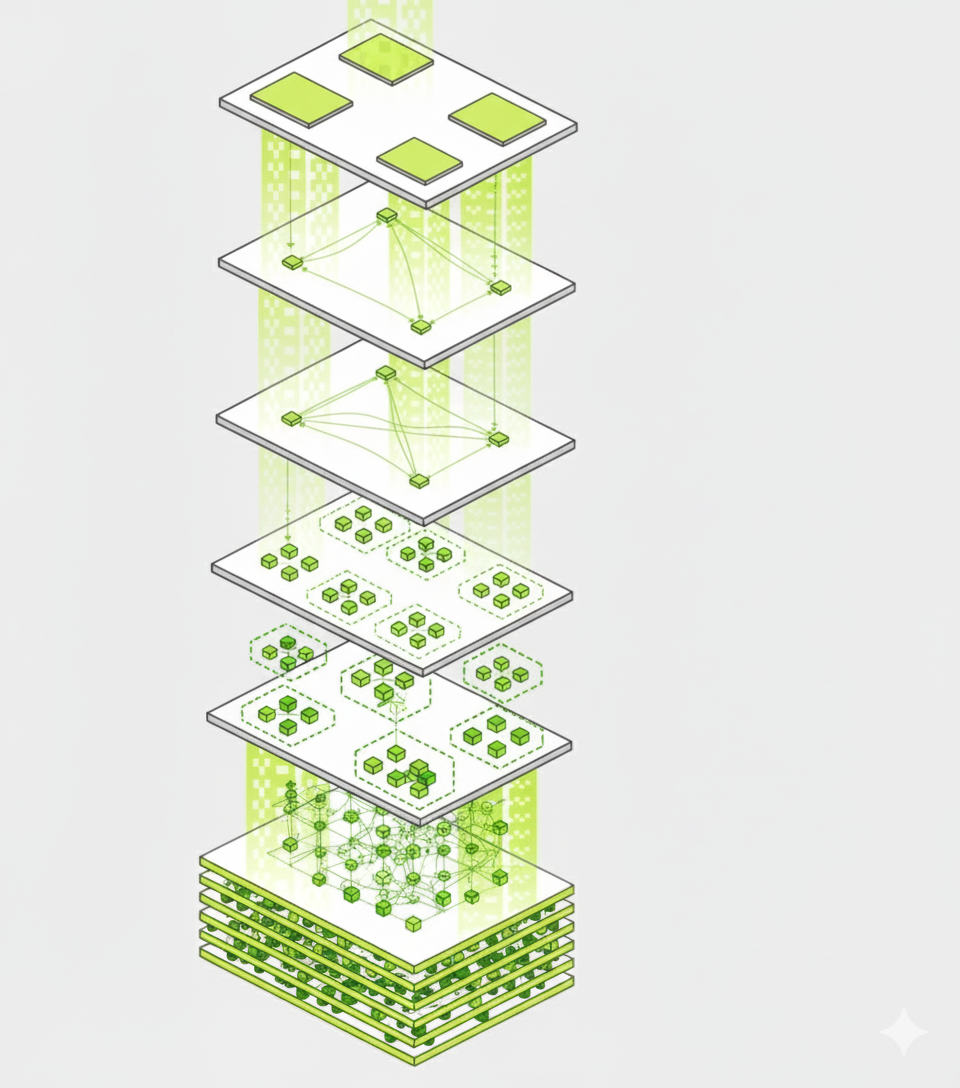
Stage 1: Binary Decomposition
Stage 2: Structure Extraction
class WorkbookStructure:
sheets: List[SheetMetadata]
named_ranges: Dict[str, CellRange]
protection_state: ProtectionInfo
external_links: List[ExternalRef]
class SheetMetadata:
name: str
dimensions: Tuple[int, int] # rows x columns
used_range: CellRange
sections: List[Section] # headers, data, totals
table_boundaries: List[TableDef]
pivot_tables: List[PivotDef]
hidden: bool
protected: bool
Stage 3: Formula Parsing (The Hard Part)
class FormulaParser:
def parse(self, formula: str) -> FormulaAST:
"""
Most tools see: "=SUMIFS(Revenue,Date,'>='&DATE(2026,1,1),Region,A2)"
And stop there.
We build a full abstract syntax tree:
- What function? (SUMIFS)
- What's the logic? (Date >= start of year, filtered by region)
- What are the dependencies? (Revenue range, Date range, Region, A2)
- What's the semantic type? (Year-to-date revenue by region)
"""
tokens = self.tokenize(formula)
ast = self.build_ast(tokens)
typed_ast = self.type_inference(ast)
return typed_ast
Stage 4: Dependency Resolution
class DependencyGraph:
def build(self, workbook: ParsedWorkbook) -> nx.DiGraph:
"""
This is where we map the computational graph.
We need to know:
- Which cells depend on which other cells?
- What happens if I change cell A1?
- Are there circular references?
- What's the calculation order?
"""
graph = nx.DiGraph()
for sheet in workbook.sheets:
for cell in sheet.cells_with_formulas:
deps = self.extract_dependencies(cell.formula_ast)
for dep in deps:
if dep.is_indirect:
# Handle INDIRECT, OFFSET, etc.
possible_refs = self.resolve_dynamic(dep)
for ref in possible_refs:
graph.add_edge(
ref, cell.address,
type='dynamic',
confidence=ref.confidence
)
else:
graph.add_edge(
dep.address, cell.address,
type='static'
)
# Detect circular references
cycles = list(nx.simple_cycles(graph))
if cycles:
graph.graph['circular_refs'] = cycles
return graph
Stage 5: Semantic Classification
class SemanticClassifier:
def __init__(self):
self.embedder = SentenceTransformer('financial-bert')
self.ontology = FinancialOntology()
def classify_cell(self, cell: Cell, context: Context) -> Labels:
"""
This is where we map cells to financial concepts.
We're not just reading "Revenue" from a header.
We're understanding:
- Is this recognized revenue or bookings?
- Is it GAAP or non-GAAP?
- Is it ARR, MRR, or one-time?
- What time period does it represent?
"""
features = {
'formula_pattern': self.pattern_match(cell.formula),
'header_context': self.extract_headers(cell, context),
'named_range': cell.named_range,
'formatting': cell.style,
'comments': cell.comment,
'position': cell.location
}
# Multi-modal classification
scores = self.classifier.score(features)
# Domain rules (high-confidence overrides)
if 'ARR' in features['header_context']:
scores['annual_recurring_revenue'] = 0.95
return Labels(
primary=max(scores, key=scores.get),
scores=scores,
confidence=max(scores.values())
)
Stage 6: Constraint Extraction
class ConstraintExtractor:
def extract(self, workbook: ParsedWorkbook) -> List[Constraint]:
"""
Constraints are the "business physics" encoded in the model.
They come from:
- Data validation rules (dropdown lists, numeric ranges)
- Conditional formatting (if value > X, highlight red)
- IF statements in formulas (if assumption > cap, use cap)
- Comments from modelers ("discount cannot exceed 40%")
"""
constraints = []
# Data validation rules
for validation in workbook.validations:
constraints.append(Constraint(
type='validation',
field=validation.range,
rule=validation.formula,
source='data_validation'
))
# Conditional formatting (implicit constraints)
for cf in workbook.conditional_formats:
if cf.type == 'cell_value':
constraints.append(Constraint(
type='threshold',
field=cf.range,
rule=cf.condition,
source='conditional_format'
))
# Formula-encoded constraints
for formula in workbook.formulas:
if 'IF' in formula.functions:
constraints.extend(
self.extract_from_conditional(formula)
)
# Comments as business rules
for comment in workbook.comments:
if self.is_constraint_comment(comment):
constraints.append(
self.parse_natural_language_rule(comment)
)
return constraints
What Gets Extracted: The Complete Catalog
From Workbook to Reasoning Graph
interface WorkbookNode {
id: UUID;
metadata: {
filename: string;
author: string;
lastModified: timestamp;
version: string;
};
structure: {
sheets: SheetNode[];
namedRanges: NamedRange[];
externalLinks: ExternalRef[];
};
formulas: {
count: number;
complexity_score: number;
dependency_graph: Graph;
semantic_index: VectorIndex;
};
metrics: {
financial_entities: Entity[];
time_periods: Period[];
business_metrics: Metric[];
};
constraints: Constraint[];
quality: {
completeness: number;
consistency: number;
accuracy: number;
};
}
Multi-Modal Reasoning: When All Modalities Connect
The Problem: Artifacts Live in Silos
The Cognitive Mesh
reasoning_graph:
- node: "Q4_Forecast.xlsx"
type: workbook
contains:
- metric: "ARR Growth"
value: "15%"
location: "Assumptions!B12"
- node: "Enterprise_Contract_Acme.pdf"
type: contract
contains:
- clause: "Payment Terms"
content: "Net 60 days"
page: 3
- node: "Email: CFO Approval"
type: email
contains:
- decision: "Approved 15% ARR growth"
rationale: "Based on pipeline coverage of 2.3x"
timestamp: "2026-01-15"
- node: "Slack: #fp-a"
type: conversation
contains:
- context: "Churn discussion"
insight: "Enterprise churn elevated due to budget cuts"
confidence: 0.87
edges:
- source: "Q4_Forecast.xlsx:Assumptions!B12"
target: "Email: CFO Approval:decision"
type: "approved_by"
- source: "Enterprise_Contract_Acme.pdf:Payment Terms"
target: "Q4_Forecast.xlsx:Cash_Flow!D45"
type: "defines_assumption"
- source: "Slack: #fp-a:insight"
target: "Q4_Forecast.xlsx:Churn!C8"
type: "explains_variance"
response = helix.explain("Why did we increase churn assumptions in Q4?")
# Returns in 3 seconds:
{
"answer": "Churn assumption increased from 3% to 5% due to elevated enterprise churn",
"evidence": [
{
"source": "Q4_Forecast.xlsx",
"location": "Churn!C8",
"formula": "=Historical_Churn*1.67",
"change": "3.0% → 5.0%"
},
{
"source": "Slack: #fp-a",
"message": "Enterprise churn elevated due to budget cuts",
"author": "Jane (VP Sales)",
"date": "2026-01-12"
},
{
"source": "Email: CFO Approval",
"decision": "Approved elevated churn assumption",
"rationale": "Conservative approach given macro uncertainty"
}
],
"impact": {
"arr_forecast": "-$2.3M",
"revenue": "-$1.8M",
"runway": "-1.2 months"
}
}
What This Unlocks
1
2
3
4
5
Cloud-Native Scale & Infrastructure
Our Processing Stack — Fully Cloud Native
GKEKubernetesAutoscaling
Vertex AIBigQueryMatching Engine
TensorFlowGPU NodesVertex AI
Why This Gets Better Over Time
More Formulas → Better Pattern Recognition
Regulatory Knowledge as Constraints
Why Now: The Convergence Moment
1. Context Windows Hit Enterprise Scale
2. Structured Output Becomes Reliable
3. Enterprise AI Reaches the Core
Common Questions re: our Finance & Excel Modalities
Closing: Infrastructure for the Intelligence Age
— Carl Jung
Related Posts
SEO & Content Strategy
From Keywords to Concepts - Semantic Analytics Turns an Earnings Preview into a Blueprint
Oct 15, 202510 min read
#semantic-seo#content-strategy#rtl
Read more
Applied Intelligence
From Keywords to Knowledge Graphs - 9 Minutes of Amazon Analysis into Queryable Intelligence
Oct 16, 20258 min read
#semantic-analytics#multimodal-processing#ai-native-kms
Read more
Announcement
Welcome to the Helix AI Blog — Engineering the Future of Multi-Modal Intelligence
Oct 1, 20255 min read
#multi-modal#ai#automation
Read more